[ python ] pandas read & count & value_counts()
본문
pandas read & count
import pandas as pd
population_number=pd.read_csv("population_number.csv", index_col="도시", encoding="euc-kr")
population_number
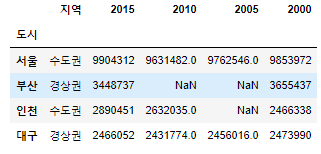
#각 컬럼별 데이터 개수 세기
population_number.count()
지역 4
2015 4
2010 3
2005 2
2000 4
dtype: int64
#Series 클래스에 들어있는 각각의 값이 몇개씩 들어있는지 셀 수 있다.
#같은 의미로 특정값 별로 몇개가 있는지 확인하는 것(value_counts())
population_number['2000'].value_counts()
2473990 1
3655437 1
9853972 1
2466338 1
Name: 2000, dtype: int64
s1 = pd.Series([1,1,2,2,3,4,5,6,6,6])
s1.value_counts()
6 3
2 2
1 2
5 1
4 1
3 1
dtype: int64
#오름차순 정렬(sort_values의 기본값은 ascending=True)
population_number['2010'].sort_values()
도시
대구 2431774.0
인천 2632035.0
서울 9631482.0
부산 NaN
Name: 2010, dtype: float64
#내림차순 정렬
population_number['2010'].sort_values(ascending=False)
도시
서울 9631482.0
인천 2632035.0
대구 2431774.0
부산 NaN
Name: 2010, dtype: float64
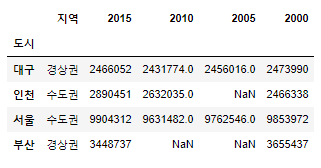
#dataFrame 클래스에 sort_values 적용
#2010을 기준으로 오름차순
#정렬과 상관없이 NaN 값은 마지막에 출력 됨
population_number.sort_values(by='2010')
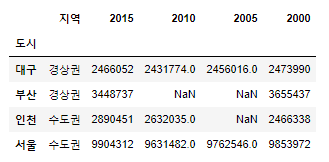
#DataFrame클래스에 sort_values 적용
population_number.sort_values(by=['지역', '2010'])
댓글목록 0
등록된 댓글이 없습니다.